52th Petnehazy Str.
Budapest, H-1139, Hungary
Office phone: +36 1 299 0763
Fax: +36 1 299 0812
E-mail: info@print-net.hu
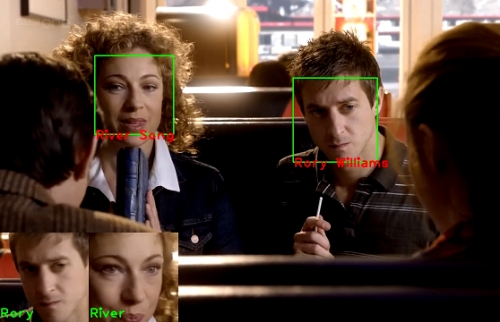

Every face recognition algorithm requires a phase in which people are taught, this is called the training phase. It means creating such a data set of every person to learn that defines the features to look for.
VisualArea SDK needs at least 10 but preferably more images taken of the face of the person to learn, which are as varied as possible. Try to keep the training set balanced; which means use the same amount of images for every person to learn. There is no use in using the exact same image of a person several times or using images that are almost identical. Images may be made from different distances (within a range the person is clearly recognizable by a human), the roll and pitch values of the face should remain within 20°, while the yaw value may extend up to 30°. It is important that each training image contain one and only one face. The background does not matter much, but it’s better if varied.
The set of the training faces are never stored, only learned. During the training SURF points are extracted from the faces, they are ordered, and the less significant ones are discarded. The result set of points is stored. This way you get one training point set for every person, which means only one comparison per face when performing recognition or authentication. It results better time performance, which can be cruel when going through several training images.
Adding a new image to the training set of a person would mean extending the existing point set, but as long as weak points are always discarded during training time it would not allow us to find the less significant ones from the whole set, because some of those were deleted during the previous learning. As a conclusion training of a person always needs to remove any existing training set of the given person, and teaching the system by using the whole – now extended – set of images. It only takes 5-10 seconds to learn a person which is not much as you only train once.